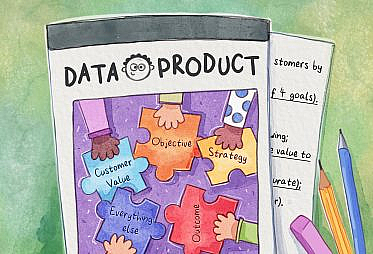
Or: How perspective changes when you’re the one asking the questions
Four years ago, I would have rolled my eyes at myself. Hard.
Back then, on the data team, I had strong opinions about the right way to access data. Product managers who wanted to query the production database replica instead of using our carefully crafted data warehouse? They were wrong. They were bypassing all the work we’d done to clean, validate, and structure the data. They were missing the
…