
In part 2 of this series, we learned that every new initiative a team undertakes should be accompanied by an expectation on how the initiative will perform. For example,
…Blog Posts

The MBR meeting is the focal point of the MBR program. Here you will publicly interrogate KPIs, align on action items and hold people accountable. There are typically
…
Getting regular feedback from your organization can help the data team to prioritize the work that will have the biggest impact on your stakeholders. However, it’s hard to turn ad-hoc
…
KPIs are central to the business review program since they provide a way to reason about the success or failure of an initiative. Core to the success of a
…
As an analytics leader, my job is to ensure that my organization makes the best data-driven decisions possible. One effective mechanism that I employ — and other analytics leaders can too — is the business review program. This program is a rigorous and systematic review of the most important Key Performance Indicators (KPIs) across the company, with involvement by senior leadership in an ongoing and iterative fashion, punctuated by a regularly occurring cross-functional meeting. …
It’s becoming more and more clearly recognized that the promises of the machine-learning revolution, at least for your average non-big-tech company, are not delivering the value that many had hoped
…
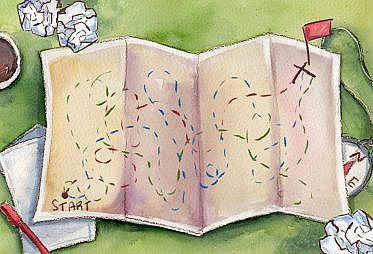
The nuances of data projects add an extra layer of challenge to project planning and agile project management approaches. Even the most efficient data team must manage the inherent moving-target
…
There’s been a lot of discussion lately about systems for doing version control for data. Most recently, Ryan Gross wrote a blog post “The Rise of DataOps” where he
…